关闭socket分为主动关闭(Active closure)和被动关闭(Passive closure)两种情况。前者是指有本地主机主动发起的关闭;而后者则是指本地主机检测到远程主机发起关闭之后,作出回应,从而关闭整个连接。
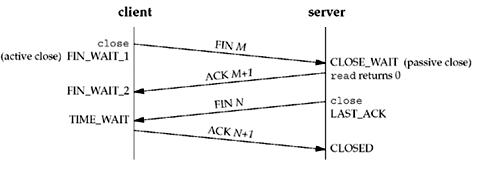
前者将会产生TIME_WAIT,而后者,则会产生CLOSE_WAIT
##产生原因
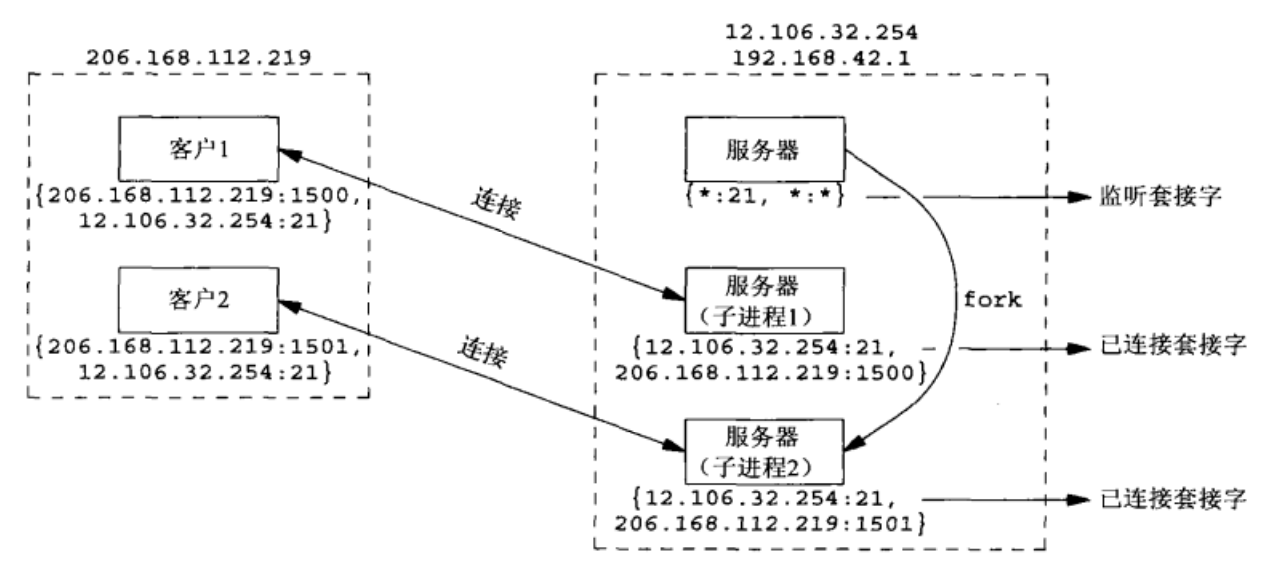
服务器A是一台爬虫服务器,它使用简单的HttpClient去请求资源服务器B上面的apache获取文件资源,正常情况下,如果请求成功,那么在抓取完资源后,服务器A会主动发出关闭连接的请求,这个时候就是主动关闭连接,服务器A的连接状态我们可以看到是
TIME_WAIT。如果一旦发生异常呢?假设请求的资源服务器B上并不存在,那么这个时候就会由服务器B发出关闭连接的请求,服务器A就是被动的关闭了连接,如果服务器A被动关闭连接之后程序员忘了让HttpClient释放连接,那就会造成CLOSE_WAIT的状态了。
在被动关闭连接情况下,在已经接收到FIN,但是还没有发送自己的FIN的时刻,连接处于CLOSE_WAIT状态。
通常来讲,CLOSE_WAIT状态的持续时间应该很短,正如SYN_RCVD状态。但是在一些特殊情况下,就会出现连接长时间处于CLOSE_WAIT状态的情况。
出现大量close_wait的现象,主要原因是某种情况下对方关闭了socket链接,但是我方忙与读或者写,没有关闭连接。代码需要判断socket,一旦读到0,断开连接,read返回负,检查一下errno,如果不是AGAIN,就断开连接。
##解决方法
基本的思想就是要检测出对方已经关闭的socket,然后关闭它。
代码需要判断socket,一旦read返回0,断开连接,read返回负,检查一下errno,如果不是AGAIN,也断开连接。(注:在UNP 7.5节的图7.6中,可以看到使用select能够检测出对方发送了FIN,再根据这条规则就可以处理CLOSE_WAIT的连接)
给每一个socket设置一个时间戳last_update,每接收或者是发送成功数据,就用当前时间更新这个时间戳。定期检查所有的时间戳,如果时间戳与当前时间差值超过一定的阈值,就关闭这个socket。
使用一个Heart-Beat线程,定期向socket发送指定格式的心跳数据包,如果接收到对方的RST报文,说明对方已经关闭了socket,那么我们也关闭这个socket。
设置SO_KEEPALIVE选项,并修改内核参数(前提是启用socket的KEEPALIVE机制)
##如果服务器出了问题
如果服务器出了异常,百分之八九十都是下面两种情况:
- 服务器保持了大量TIME_WAIT状态
- 服务器保持了大量CLOSE_WAIT状态
因为linux分配给一个用户的文件句柄是有限的,而TIME_WAIT和CLOSE_WAIT两种状态如果一直被保持,那么意味着对应数目的通道就一直被占着,而且是“占着茅坑不使劲”,一旦达到句柄数上限,新的请求就无法被处理了,接着就是大量Too Many Open Files异常,tomcat崩溃。。。
网上有很多资料把这两种情况的处理方法混为一谈,以为优化系统内核参数就可以解决问题,其实是不恰当的,优化系统内核参数(/etc/sysctl.conf)解决TIME_WAIT可能很容易,但是应对CLOSE_WAIT的情况还是需要从程序本身出发。