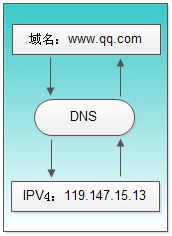
diff -urNa dir1 dir2
-a: Treat all files as text and compare them line-by-line, even if they do not seem to be text.
-N: In directory comparison, if a file is found in only one directory, treat it as present but empty in the other directory.
-r: When comparing directories, recursively compare any subdirectories found.
-u: Use the unified output format.