class Article(models.Model):
title = models.CharField(max_length=1024, default='')
...
def __str__(self):
return 'Article pk:%d %s' % (self.pk, self.title[:30])
class ArticleContent(models.Model):
article = cached_fields.OneToOneField(Article)
...
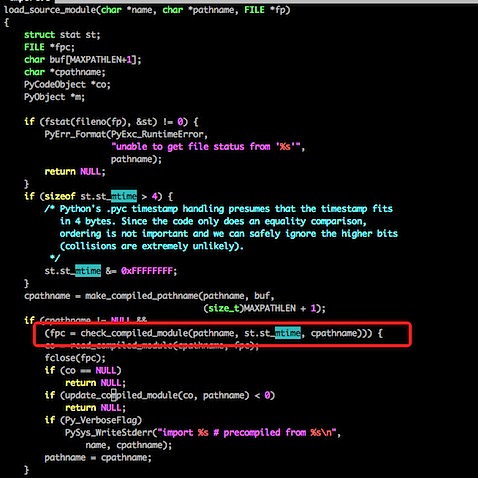
写代码的的时候,发现了一个很奇怪的现象,当我给一个instance的外键(以_id结尾)赋值(数字)的时候 ,这个外键对应的instance的值并不会改变。
In [44]: ac = ArticleContent.objects.get(article_id=14269)
In [45]: ac.article_id
Out[45]: 14269
In [46]: ac.article_id = 14266
In [47]: ac.save()
In [48]: ac.article
Out[48]: <Article: Article pk:14266 EC: Russia, Ukraine to Meet in>
In [49]: ac.article.pk
Out[49]: 14266
如上面的代码所示,为了找到答案,我翻了一下Django的源码:
django/db/models/fields/related_descriptors.py
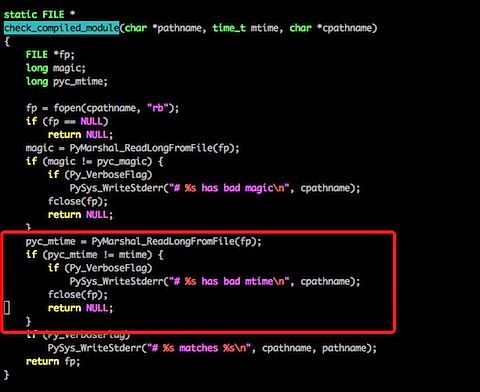
145 def __get__(self, instance, cls=None):
146 """
147 Get the related instance through the forward relation.
148
149 With the example above, when getting ``child.parent``:
150
151 - ``self`` is the descriptor managing the ``parent`` attribute
152 - ``instance`` is the ``child`` instance
153 - ``cls`` is the ``Child`` class (we don't need it)
154 """
155 if instance is None:
156 return self
157
158 # The related instance is loaded from the database and then cached in
159 # the attribute defined in self.cache_name. It can also be pre-cached
160 # by the reverse accessor (ReverseOneToOneDescriptor).
161 try:
162 rel_obj = getattr(instance, self.cache_name)
163 except AttributeError:
164 val = self.field.get_local_related_value(instance)
165 if None in val:
166 rel_obj = None
167 else:
168 qs = self.get_queryset(instance=instance)
169 qs = qs.filter(self.field.get_reverse_related_filter(instance))
170 # Assuming the database enforces foreign keys, this won't fail.
171 rel_obj = qs.get()
172 # If this is a one-to-one relation, set the reverse accessor
173 # cache on the related object to the current instance to avoid
174 # an extra SQL query if it's accessed later on.
175 if not self.field.remote_field.multiple:
176 setattr(rel_obj, self.field.remote_field.get_cache_name(), instance)
177 setattr(instance, self.cache_name, rel_obj)
178
179 if rel_obj is None and not self.field.null:
180 raise self.RelatedObjectDoesNotExist(
181 "%s has no %s." % (self.field.model.__name__, self.field.name)
182 )
183 else:
184 return rel_obj
注释得非常到位,当我们请求ac.article的时候,会先去检查对应的cache(在这里是_article_cache,感兴趣可以去看cache_name的生成规则,就是外键名前面加下划线,后面加cache)存不存在,如果不存在那么就进行数据库请求,请求完之后会保存到cache中。
我们再看看__set__,代码太长就不贴了(就在__get__方法下面)。除了给外键字段(article)赋值外,还会将pk字段(article_id,是lh_field.attname的值)设置为None,这样下次请求的时候就能拿到正确的值。
以上都是ForeignKey的Magic,而当我们给article_id赋值的时候,只是在给一个普通的attribute赋值而已,没有任何magic,不会清理对应外键的cache,这时候拿到的instance仍然是cache中原来的那个instance。