- get和post的区别
- GET用于信息获取,而且应该是安全的和幂等的,POST表示可能修改变服务器上的资源的请求
- GET方式提交的数据最多只能是1024字节,理论上POST没有限制,可传较大量的数据
- POST提交,把提交的数据放置在是HTTP包的包体中,GET提交的数据会在地址栏中显示出来
- 一个广域网和一个局域网相连,需要的设备是
路由器,网关 - 在Web开发中,如何实现会话的跟踪
- 隐藏表单域
- 保存cookie
- URL复写
- session 机制
- cookie和session
- cookie数据存放在客户的浏览器上,session数据放在服务器上。
- session是针对每一个用户的,变量的值保存在服务器上,用一个sessionID来区分是哪个用户session变量
- 保存这个session id的方式可以采用cookie
- cookie 属性的一些描述:
- expires: cookie的过期时间
- domain属性可以使多个web服务器共享cookie
- path属性指定与cookie关联在一起的网页
- secure: 如果secure 这个词被作为Set-Cookie 头的一部分,那么cookie 只能通过安全通道传输
- dns域名劫持
- 如果dns把你想要解析的地方,解析为错误的另一个地方,这种现象叫做dns劫持
- 如果知道该域名的真实IP地址,则可以直接用此IP代替域名后进行访问
- 可以通过更换其它DNS解决域名劫持问题
linux-一些小面试题
- 创建.tar.gz的参数时c,解压的参数是x
代码如下
int main { char *p = "hello world"; return 0; }p和”hello,world”存储在内存哪个区域?
答:栈,只读存储区;根据C语言中的特性和定义,p是一个局部变量,而C语言中局部变量存在于栈中,”hello wrold”是一个字符串字面常量,因此存储于程序的只读存储区中,p在这里其实只是指向了”hello wrold”在只读存储区中的地址而已。- Linux中,一个端口能够接受tcp链接数量的理论上限是:无上限
- 在OSI模型中,HTTP协议工作在第
6层:表示层,交换机工作在第2层:数据链路层 - 查看linux系统运行了多长时间的命令是:uptime
- UNIX系统中进程由三部分组成:进程控制块,正文段和数据段。这意味着一个程序的正文与数据可以是分开的,这种分开的目的是为了
- 可共享内存
- 可共享数据
- 可重入
- 批处理操作系统的目的是:提高系统资源利用率
找出N个整数中最大的K个数
顺序读取数组中的前K个元素,构建小根堆。
小根堆的特点是根元素最小,并且一次调整(deleteMin)操作的时间复杂度为log(2,K)。
接下来从数组中取下一个元素,如果该元素不比堆顶元素大,则丢弃;否则用它替换堆顶元素,然后调整小根堆。
当把数组中的元素全部读出来后,小根堆中保留的就是前K大的元素。
初始建堆操作需要K * log(2, k)–这是最多的操作次数,从数组中读取后N-K个元素和堆顶元素一一比较,最坏的情况是每次都要替换堆顶元素,都要调整小根堆,复杂度为(N-K) * log(2,K)。总的复杂度为O(N*log(2,K))。
###找出最小的k个数呢?
和最大的k个数的思想是相同的,只是这里建立的是是大根堆
fork-面试题
这是EMC的一道面试题
|
|
本题有两个知识点:
- 对逻辑运算符的理解
- 对fork的理解
如果是A && B || C这样一个表达式,运行情况是怎样的呢?
- A为0,不再判断B,直接判断C
- A不为0
- B为0,继续判断C
- B为1,不再判断C
fork调用的奇妙之处在于他被调用一次,会返回两个值
- 在父进程中,返回新创建进程的ID
- 在子进程中,返回0
下面来分析fork() && fork() || fork()创建了几个进程
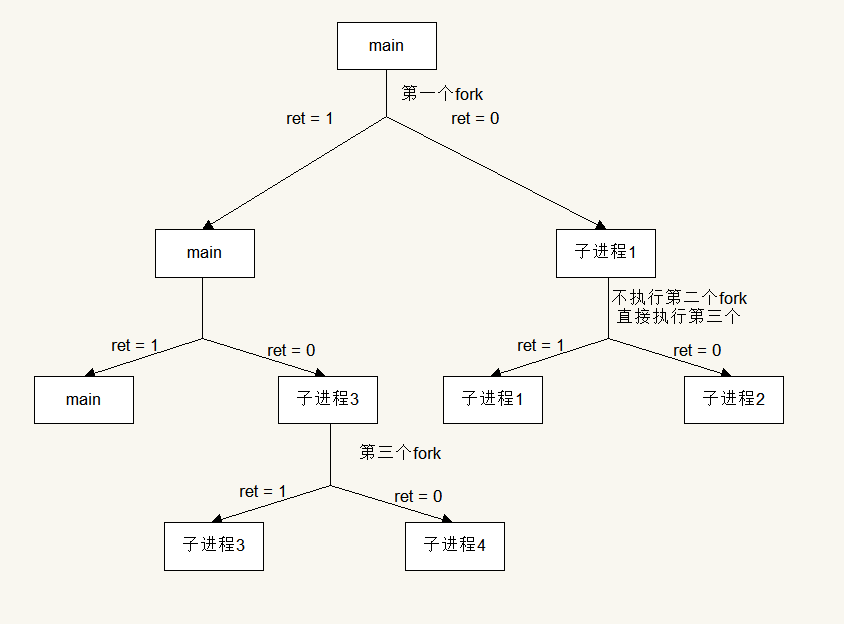
很明显,fork() && fork() || fork()创建了4个进程
c语言const总结
###前言:const意味着只读,凡修改了const不允许修改的东西,编译器报错
##const修饰指针
const修饰指针可以分为如下的四种情况:
int b = 5;
const int *a = &b; //情况1
int const *a = &b; //情况2
int* const a = &b; //情况3
const int * const a = &b; //情况4
而这四种情况,总结一下,其实只有两种情况:
- const位于
*的左侧,则const是修饰指针所指向的变量,即指针指向为常量 - const位于
*的右侧,const就是修饰指针本身,即指针本省是常量
本质:const在谁后面谁就不可修改,const在最前面则将其后移一位即可,二者等效
所以情况1和情况2是相同的,都是指针所指向的内容为常量(const放在变量声明符的位置无关),这种情况下不允许通过指针改变指针指向的内容
int b = 5;
const int *a = &b;
*a = 6; //编译报错:错误:向只读位置‘*a’赋值
如果想要改变*a的值怎么办呢?有两种方法
//方法一:改变b的值
int b = 5;
const int *a = &b;
b = 6;
printf("%d", *a); //输出6
//方法二:让*a指向别处
int b = 5, c = 6;
const int *a = &b;
a = &c;
printf("%d", *a);//输出6
因为const int a是说指针指向的内容为常量,指针本身并不是常量,所以可以不初始化
const int a; //正确
情况3为指针本身为常量,这种情况下不能对指针本身的值进行更改,即指针初始化指向哪里,在指针的整个生命中都将指向那个地址,不会改变。但是指针指向的地址的内容不是常量。所以我们应该可以理解,情况3中的指针定义时必须初始化
int b = 5, c = 6;
int *const a; //在下面给a赋值时会出错:错误:向只读变量‘a’赋值
int *const a = &b; //初始化
*a = 6; //正确,允许修改值
printf("a new address is %d", a++); //编译出错:错误:令只读变量‘a’自增
至于情况4,就是情况1和情况3的合体了,既不允许修改指针的值,也不允许修改指针指向的值
##const修饰函数
如果以指针传递方式的函数返回值加const修饰,那么函数返回值(即指针)的内容不能被修改,该返回值只能被赋给加const修饰的同类型指针
##同样都可以定义常量,const与#define相比有什么不同?
const相对于#define的有点在于:
- const常量有数据类型,而宏常量没有数据类型
- 编译器可以对const常量进行类型安全检查,而对后者只进行字符替换,没有安全检查,而且在字符替换过程中可能会产生意想不到的错误(边际效应)
sizeof-面试题
下面是一道笔试题:
|
|
在64位linux系统上此程序的输出为:
8 11 100 400 4 3 8 6 16 8 8
在32位机上的输出为:
4 11 100 400 4 3 4 6 8 4 4
解释:32位机器上long和int都是4字节,64位机器上,long是8字节,int是4字节
sizeof和strlen之间的区别
接上面的例子分析:
|
|
总结
- sizeof操作符的结果类型时size_t,它在头文件中的typedef为unsigned int类型。该类型保证能容纳实现所建立的最大对象的字节大小
再来一题
|
|
输出:“20, 4, 4”。data1是一个数组,sizeof(data1)是求数组的大小。这个数组包含5个整数,每个整数占4字节,因此总共是20字节。data2声明为指针,尽管它指向了数组data1的第一个数字,但它的本质仍然是一个指针。在32位系统上,对任意指针求sizeof,得到的结果都是4。在C/C++中,当数组作为函数的参数进行传递时,数组就自动退化为同类型的指针。因此尽管函数GetSize的参数data被声明为数组,但它会退化为指针,size3的结果仍然是4。—《剑指offer》P37
exceptions.ValueError Missing scheme in request url h
用scrapy写的爬虫把抓到的图片下载下来时,报了这个错,从字面上看使我们的url除了问题,那究竟是什么错误呢?下面是错误的代码:
item['image_urls'] = sel.xpath('.//*[@class="postmessage defaultpost"]//img/@src').extract()[0]
我们可以在shell里面试一下,这句代码是能够提取出正确的url的。但是提取出来的url却不是item需要的格式。stackoverflow上有关于这个问题的回答,正确的写法应该是这个样子的:
item['image_urls'] = [sel.xpath('.//*[@class="postmessage defaultpost"]//img/@src').extract()[0]]
解释一下,item的image_urls是一个字典,错误的代码中,它把图片的链接http://*****.jpg当作了一个字典,第一个元素自然是h,而它真实想要的是http一样的协议名,所以报错如上。只要在url外面加[],整个url就会被当成整体,就能正常运行了
scrapy防止被ban的策略
转载自这里
1. 设置download_delay
他的作用主要是设置下载的等待时间,大规模集中的访问对服务器的影响最大,相当于短时间中增大服务器负载。下载等待时间长,不能满足短时间大规模抓取的要求,太短则大大增加了被ban的几率。如果你的爬虫工作的好好的,突然掉线了,并且得到了类似下面的错误:
|
|
不妨试着将download_delay设置的大一点。
使用注意:
download_delay可以设置在settings.py中,也可以在spider中设置
2. 禁止cookies
所谓cookies,是指某些网站为了辨别用户身份而储存在用户本地终端(Client Side)上的数据(通常经过加密),禁止cookies也就防止了可能使用cookies识别爬虫轨迹的网站得逞。
使用:
在settings.py中设置COOKIES_ENABLES=False。也就是不启用cookies middleware,不向web server发送cookies
3. 使用user agent池
所谓的user agent,是指包含浏览器信息、操作系统信息等的一个字符串,也称之为一种特殊的网络协议。服务器通过它判断当前访问对象是浏览器、邮件客户端还是网络爬虫。在request.headers可以查看user agent。如下,使用scrapy shell查看:
scrapy shell http://michaelyou.github.io
输出request.headers可以得到如下信息
|
|
由此得到,scrapy本身是使用Scrapy/0.24.4来表明自己身份的。这也就暴露了自己是爬虫的信息。解决方法如下:
首先编写自己的UserAgentMiddle中间件,在spider目录下新建rotate_useragent.py,代码如下:
|
|
建立user agent池(user_agent_list)并在每次发送request之前从agent池中随机选取一项设置request的User_Agent。编写的UserAgent中间件的基类为UserAgentMiddle。
除此之外,要在settings.py(配置文件)中禁用默认的useragent并启用重新实现的User Agent。配置方法如下:
取消默认的useragent,使用新的useragent
|
|
4. 使用IP池
web server应对爬虫的策略之一就是直接将你的IP或者是整个IP段都封掉禁止访问,这时候,当IP封掉后,转换到其他的IP继续访问即可。
可以使用Scrapy+Tor+polipo
配置方法与使用教程请点这里。
5. 分布式爬取
有时间再补充
一些常用的shell和vim命令
删除一个目录下所有某个格式的文件
find . -name "*.pyc" -type f -print -exec rm -rf {} \; find . -name "*.pyc" -type f -print0 | xargs -0 rm -f //-print0选项将'\0'作为find输出的分隔符 //xargs -0将'\0'作为输入定界符把文件夹内所有文件中的一个字符串替换成另外一个字符串
sed -i "s/descritpion/scription/g" `grep descritpion -rl .` //将文件夹所有文件中的descritpion替换成scription统计代码行数
find -type f -name '*.c' -print0 | xargs -0 wc -l //此命令可以找到路径下所有c文件,并统计行数(双引号必不可少) //wc -l 统计一个文件的行数vim的全文替换
在:下,命令1,$s/he/you/g 将文件中的he替换成you,其中$表示到文件最后一行
在scrapy提供的shell中测试xpath
scrapy的Rule定义了从html中取url的规则,但是这些url是被自动提取,也无法打印,如果xpath有误很难调试。下面提供一种方法可以在scrapy的shell中测试LinkExtractor的xpath的正确性
1.scrapy shell 'url'
2.from scrapy.contrib.linkextractors import LinkExtractor
3.item= LinkExtractor(allow=('***'),restrict_xpaths=('***')).extract_links(response)
4.for i in item:
print i.text
这样就可以打印出从response中提取的url了,注意得到的item是一个list,所以要循环遍历