##QUESTION
定义一个函数,输入一个链表的头结点,反转该链表并输出反转后链表的头结点。
##SOLUTION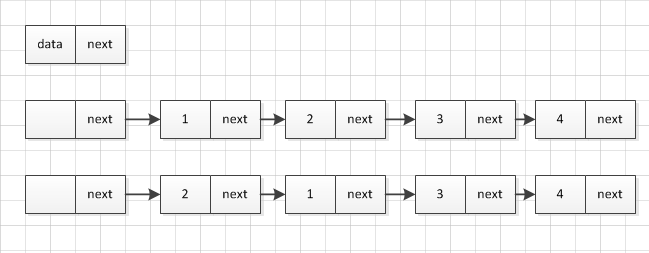
反转这个单链表的基本思想是,不断地将后面的结点移到head后面来,下面以反转结点1和结点2作为例子:
- 头结点的next指向结点2
- 结点1的next指向结点3
- 结点2的next指向结点1
这样就完成了一次交换,顺序变成了head->结点2->结点1->结点3->结点4->NULL,下面我们进行相同的操作将结点3移到head之后,然后将结点4移到head之后,就完成了反转,下面是代码:
typedef struct Node
{
int data;
struct Node *next;
}*node;
node reverse_list(node head)
{
node p, q;
if(head == NULL)
return NULL;
printf("the old list is:");
print_list(head);
p = head->next;
while(p != NULL && p->next != NULL)
{
q = p->next;
p->next = q->next;
q->next = head->next;
head->next = q;
}
return head; //可有可无
}
题目的要求是返回新链表的头结点,在这里,新链表的头结点就是原来链表的头结点。所以最后一句是没有必要的,直接用head作为参数就可以打印链表。