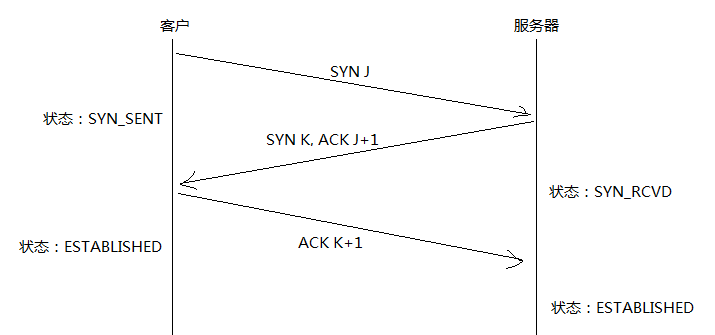
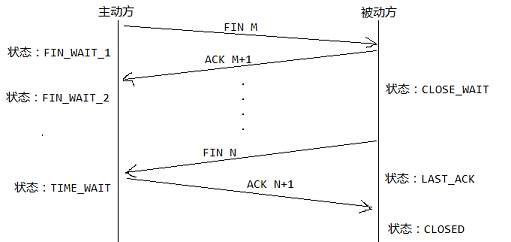
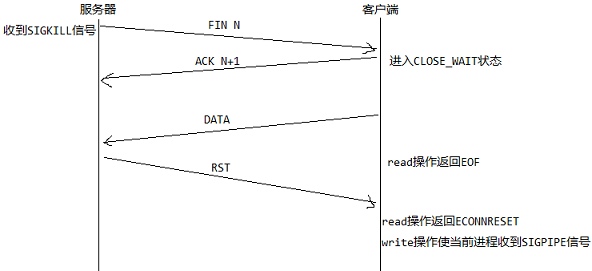
If-Modified-Since:
作用: 把浏览器端缓存页面的最后修改时间发送到服务器去,服务器会把这个时间与服务器上实际文件的最后修改时间进行对比。如果时间一致,那么返回304,客户端就直接使用本地缓存文件。如果时间不一致,就会返回200和新的文件内容。客户端接到之后,会丢弃旧文件,把新文件缓存起来,并显示在浏览器中.
ETag:
是实体标签(Entity Tag)的缩写, 根据实体内容生成的一段hash字符串(类似于MD5或者SHA1之后的结果),可以标识资源的状态。 当资源发送改变时,ETag也随之发生变化。
ETag是Web服务端产生的,然后发给浏览器客户端。浏览器客户端是不用关心Etag是如何产生的。
问题是,我们知道last-modified可以用来判断浏览器的本地缓存是否有效,那为什么还要使用ETag呢? 主要是为了解决Last-Modified 无法解决的一些问题。
某些服务器不能精确得到文件的最后修改时间, 这样就无法通过最后修改时间来判断文件是否更新了。
某些文件的修改非常频繁,在秒以下的时间内进行修改. Last-Modified只能精确到秒。
一些文件的最后修改时间改变了,但是内容并未改变。 我们不希望客户端认为这个文件修改了。