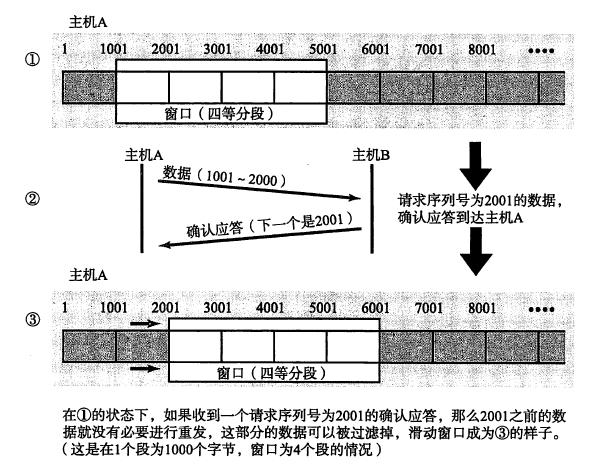
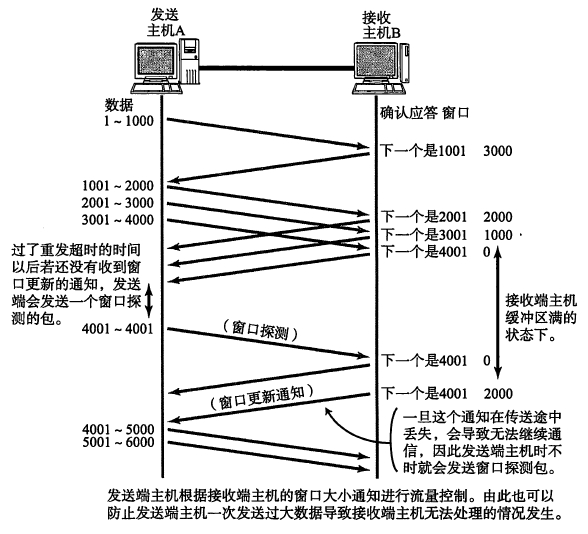
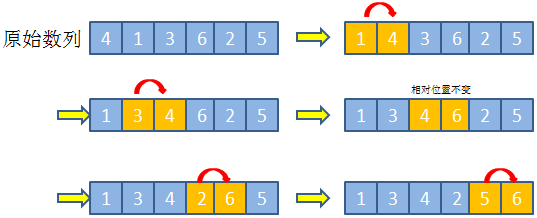
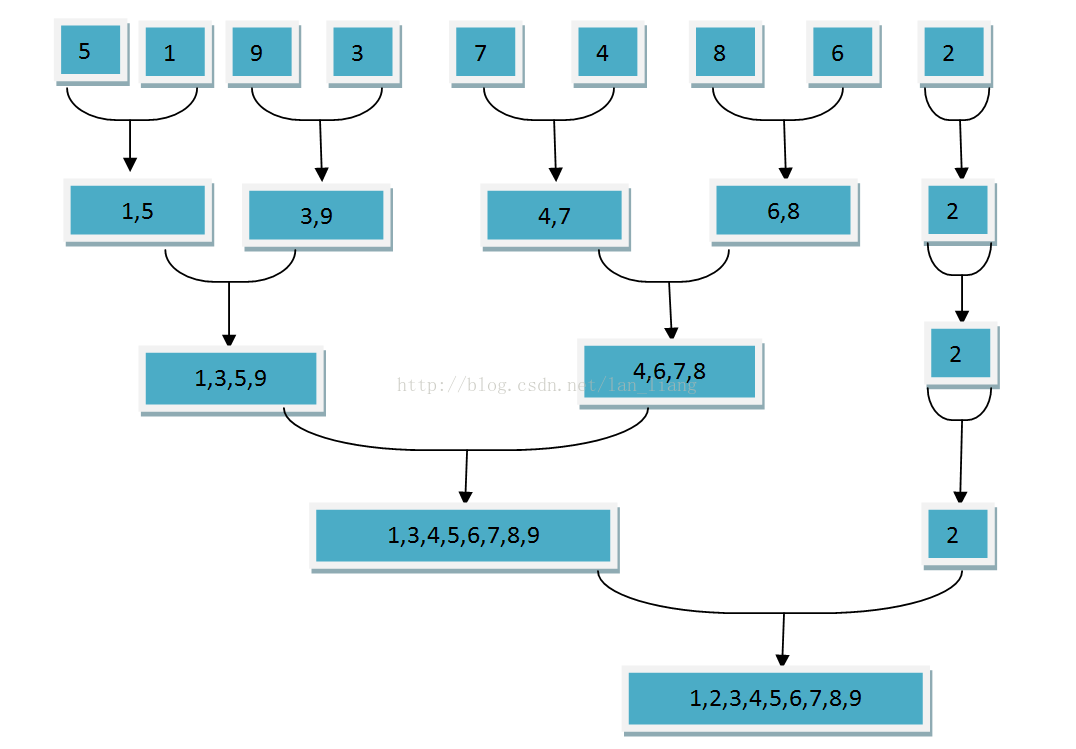
TCP 的 timewait 状态是什么?谁会有 timewait 状态?timewait 状态存在的作用是什么?如何避免大量的 timewait 状态占用系统资源?
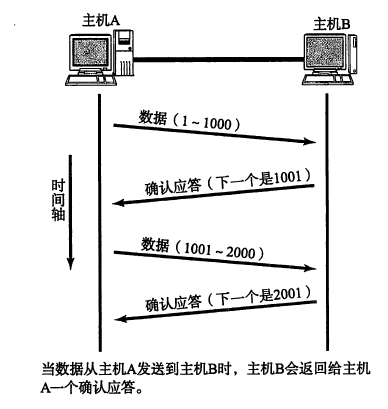
timewait 状态是 TCP 链接的主动关闭方会有的状态,在发出最后一个 ACK 包之后,主动关闭方进入 timewait 状态,以确保 ACK 包到达对端,以及等待网络中之前迷路的数据包完全消失,防止在端口被复用的时候收到迷路包从而出现收包错误。
timewait 状态会持续 2MSL(max segment lifetime) 的时间,一般会有 1分钟到4分钟事件。这段事件内 端口不可被重分配使用。
timewait 并不会占用更多系统资源,但是可以通过修改内核参数 /etc/sysctl.conf 来达到 限制timewait 数量的功能。
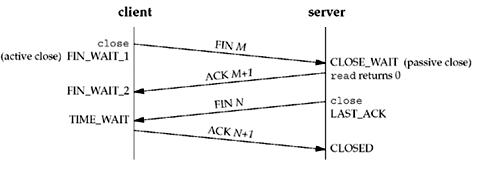
##TIME_WAIT状态原理
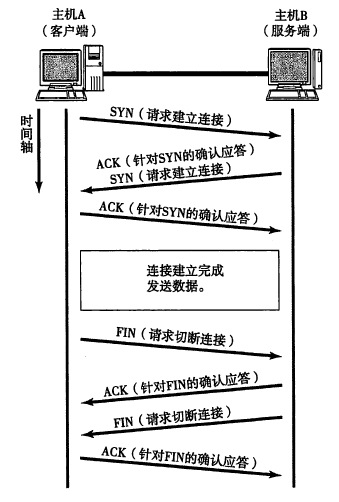
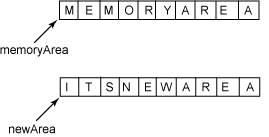
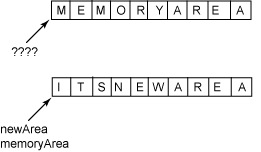
通信双方建立TCP连接后,主动关闭连接的一方就会进入TIME_WAIT状态。客户端主动关闭连接时,会发送最后一个ack,然后会进入TIME_WAIT状态,再停留2个MSL时间(后有MSL的解释),进入CLOSED状态。
上图是以客户端主动关闭连接为例,说明这一过程的。
##TIME_WAIT状态存在的理由
TCP/IP协议就是这样设计的,是不可避免的。主要有两个原因:
###可靠地实现TCP全双工连接的终止
TCP协议在关闭连接的四次握手过程中,最终的ACK是由主动关闭连接的一端(后面统称A端)发出的,如果这个ACK丢失,对方(后面统称B端)将重发出最终的FIN,因此A端必须维护状态信息(TIME_WAIT)允许它重发最终的ACK。如果A端不维持TIME_WAIT状态,而是处于CLOSED 状态,那么A端将响应RST分节,B端收到后将此分节解释成一个错误(在java中会抛出connection reset的SocketException)。
因而,要实现TCP全双工连接的正常终止,必须处理终止过程中四个分节任何一个分节的丢失情况,主动关闭连接的A端必须维持TIME_WAIT状态 。
###允许老的重复分节在网络中消逝
TCP分节可能由于路由器异常而“迷途”,在迷途期间,TCP发送端可能因确认超时而重发这个分节,迷途的分节在路由器修复后也会被送到最终目的地,这个迟到的迷途分节到达时可能会引起问题。在关闭“前一个连接”之后,马上又重新建立起一个相同的IP和端口之间的“新连接”,“前一个连接”的迷途重复分组在“前一个连接”终止后到达,而被“新连接”收到了。为了避免这个情况,TCP协议不允许处于TIME_WAIT状态的连接启动一个新的可用连接,因为TIME_WAIT状态持续2MSL,就可以保证当成功建立一个新TCP连接的时候,来自旧连接重复分组已经在网络中消逝。
MSL时间
MSL就是maximum segment lifetime(最大分节生命期),这是一个IP数据包能在互联网上生存的最长时间,超过这个时间IP数据包将在网络中消失 。MSL在RFC 1122上建议是2分钟,而源自berkeley的TCP实现传统上使用30秒。
TIME_WAIT状态维持时间
TIME_WAIT状态维持时间是两个MSL时间长度,也就是在1-4分钟。Windows操作系统就是4分钟。