原文: Improving load balancing with a new consistent-hashing algorithm
我们在云上运行Vimeo的动态视频打包器Skyfire,每天服务近10亿个DASH和HLS请求。 这个请求量是非常大的! 我们对它的表现非常满意,但将其扩展到适应今天的流量以及更高的流量是一个有趣的挑战。 今天我想谈谈一个新的算法,有限负载一致性哈希(bounded-load consistent hashing),以及它是如何消除我们视频传输的瓶颈的。
动态打包
Vimeo的视频文件存储为MP4文件,与浏览器中用于下载或“渐进式”播放的格式相同。但是,DASH和HLS不使用单个文件 - 它们使用单独的视频短片段。当播放器请求某个片段时,Skyfire会动态处理该请求。它仅获取MP4文件的必要部分,针对DASH或HLS格式进行一些调整,并将结果发送回用户。
但是,当播放器请求(例如,文件的第37段)时,Skyfire如何知道需要获取哪些字节?它需要查看一个索引,该索引知道所有关键帧的位置以及文件中的所有数据包。在索引可以被查询之前,你需要生成它。这需要至少一个HTTP请求和一点CPU时间 - 或者,对于很长的视频,需要大量的CPU时间。由于我们对同一视频文件的请求很多,因此缓存索引并在以后重复使用是有意义的。
当我们第一次在现实世界中开始测试Skyfire时,我们采用了一种简单的缓存方法:我们将索引缓存在生成它们的云服务器的内存中,并在HAProxy中使用一致性哈希将相同视频文件的请求发送到相同的云服务器。这样,我们可以重用缓存的数据。
理解一致性哈希
在继续前进之前,让我们深入研究一下一致性哈希,这是一种在多个服务器之间分配负载的技术。如果你已经熟悉一致性哈希,请随时跳转到下一部分。
要使用一致性哈希在服务器之间分发请求,HAProxy会获取部分请求的哈希值(我们使用的是包含视频ID的URL的一部分),并使用该哈希值来选择可用的后端服务器。使用传统的“模状哈希”,您只需将请求哈希值视为一个非常大的数字。如果以可用服务器数量为模数,则获取的是要使用的服务器的索引。这很简单,只要服务器列表稳定,它就能很好地工作。但是,当添加或删除服务器时,会出现问题:大多数请求将散列到与之前不同的服务器。如果你有九台服务器并且添加了十分之一,那么只有十分之一的请求会(通过运气)散列到与之前相同的服务器。
所以有了一致性哈希。一致性哈希使用更复杂的方案,其中每个服务器根据其名称或ID分配多个哈希值,并且每个请求都根据“最近”哈希值分配给服务器。这种增加的复杂性的好处是,当添加或删除服务器时,大多数请求将映射到他们之前执行的相同服务器。因此,如果您有九台服务器并添加十分之一,则大约1/10的请求将落在新添加的服务器哈希值附近,而另外9/10将落到与之前相同的最近服务器。好多了!因此,一致性哈希使我们可以添加和删除服务器,而不会完全干扰每个服务器所拥有的缓存。当这些服务器在云中运行时,这是一个非常重要的属性。
一致性哈希 - 不理想的负载均衡
但是,一致性哈希有其自身的问题:请求分布不均匀。由于其数学属性,当请求的分布均匀时,一致性哈希仅平衡负载以及为每个请求随机选择服务器。但是,如果某些内容比其他内容(互联网中很常见)更受欢迎,那可能会很糟糕。一致性哈希会将该流行内容的所有请求发送到相同的服务器,比其他服务器接收更多流量。这可能导致服务器过载,视频播放效果不佳以及用户不满意。
到2015年11月,由于Vimeo已经准备好向一群精心挑选的成员推出Skyfire,我们认为这个超载问题太严重,不容忽视,所以我们改变了缓存使用方法。我们在HAProxy中使用了“least connections”的负载均衡策略,而不是基于一致性哈希的均衡,因此负载将在服务器之间均匀分配。我们使用memcache添加了一个二级缓存,在服务器之间共享,这样一个服务器生成的索引可以被另一个服务器检索。共享缓存需要一些额外的带宽,但负载在服务器之间更均衡地平衡。这就是我们第二年愉快运行的方式。
两者都有不是更好吗?
为什么没有办法说“使用一致性哈希,但请不要超载任何服务器”?早在2015年8月,我就试图提出一种算法,该算法基于两个随机选择的功能,这样做可以做到这一点,但是一些模拟表明它不起作用。向非理想服务器发送了太多请求。我很失望,但是我们没有浪费时间去拯救它,而是采用了上面最少的连接和共享缓存方法。
快进到2016年8月。我注意到不可估量的Damian Gryski推文中的一个URL,这是一篇名为Consistent Hashing with Bounded Loads的arXiv论文。我阅读了摘要,它似乎正是我想要的:一种算法,它将一致性哈希与任何一台服务器负载的上限相结合,相对于整个池的平均负载。我读了这篇论文,算法非常简单。实际上,该论文表示:
虽然一致性哈希搭配转发来满足容量限制的想法似乎非常明显,但似乎以前没有被考虑过。
有界负载算法(The bounded-load algorithm)
这是算法的简化草图。遗漏了一些细节,如果你打算自己实现它,你一定要去原始论文获取信息。
首先,定义一个大于1的平衡因子c。c控制服务器之间允许的不平衡程度。例如,如果c = 1.25,则服务器不应超过平均负载的125%。在c增加到∞的极限中,算法变得等效于普通一致性哈希,没有平衡;当c减小到接近1时,它变得更像是最少连接策略,并且哈希变得不那么重要。根据我的经验,1.25和2之间的值更适用于实际场景。
当请求到达时,计算平均负载(未完成请求的数量,m,包括刚刚到达的请求数除以可用服务器数n)。将平均负载乘以c得到“目标负载”,t。在原始论文中,将容量分配给服务器,以便每个服务器的容量为⌊t⌋或⌈t⌉,总容量为⌈cm⌉。因此,服务器的最大容量为⌈cm/n⌉,大于平均负载的c倍,小于1个请求。为了支持给服务器不同的“权重”,正如HAProxy所做的那样,算法必须略有改变,但精神是相同的 - 没有服务器可以超过负载份额1个请求。
分发一个请求时,像往常一样计算其哈希值和最近的服务器。如果该服务器负载低于其容量,则将请求分配给该服务器。否则,转到哈希环中的下一个服务器并检查其负载,继续,直到找到有剩余容量的服务器。肯定有一个服务器符合条件,因为最高容量高于平均负载,并且每个服务器的负载不可能高于平均值。这保证了一些不错的东西:
- 不允许服务器负载超过(平均负载 * c 加 1) 个请求。
- 只要服务器未过载,请求的分配策略与一致性哈希相同。
- 如果服务器过载,则所选择的回退服务器列表对于相同的请求哈希将是相同的 - 即,相同的服务器将始终是流行的内容的“第二选择”。这对缓存很有用。
- 如果服务器过载,则回退服务器列表对于不同的请求哈希值通常会有所不同 - 即,过载服务器的溢出负载将在可用服务器之间分配,而不是全部落到某个服务器上。这取决于每个服务器在一致性哈希环中分配多少个点。
实际应用的结果
在模拟器中测试算法并获得比我的简单算法更积极的结果后,我开始搞清楚如何将其hack到HAProxy。向HAProxy添加代码并不算太糟糕。HAProxy代码非常干净,组织良好,经过几天的工作,我得到了一些运行良好的程序,我可以通过它重放一些流量,观察算法的作用。它奏效了!数学证明和模拟是很好的,但是直到你看到真正的流量击中正确的服务器才能真正相信。
有了这个成功,我在9月份向HAProxy发送了一个概念验证补丁。 HAProxy维护者Willy Tarreau(非常高兴能与之合作),认识到算法的价值。他并没有告诉我我的补丁有多糟糕。他做了彻底的代码审查,并提供了一些非常有价值的反馈。我花了一点时间来处理这些建议并把事情搞定了,几周之后我就有了一个精美的版本准备发送到列表中。还有一些小的调整,它在10月26日发布的HAProxy 1.7.0-dev5及时被接受。11月25日,HAProxy 1.7.0被指定为稳定版本,因此现在普遍可以使用有限负载一致性哈希。
但我确定你想知道的是,我们从这一切中获得了什么?
这是更改HAProxy配置之前和之后的缓存行为图。
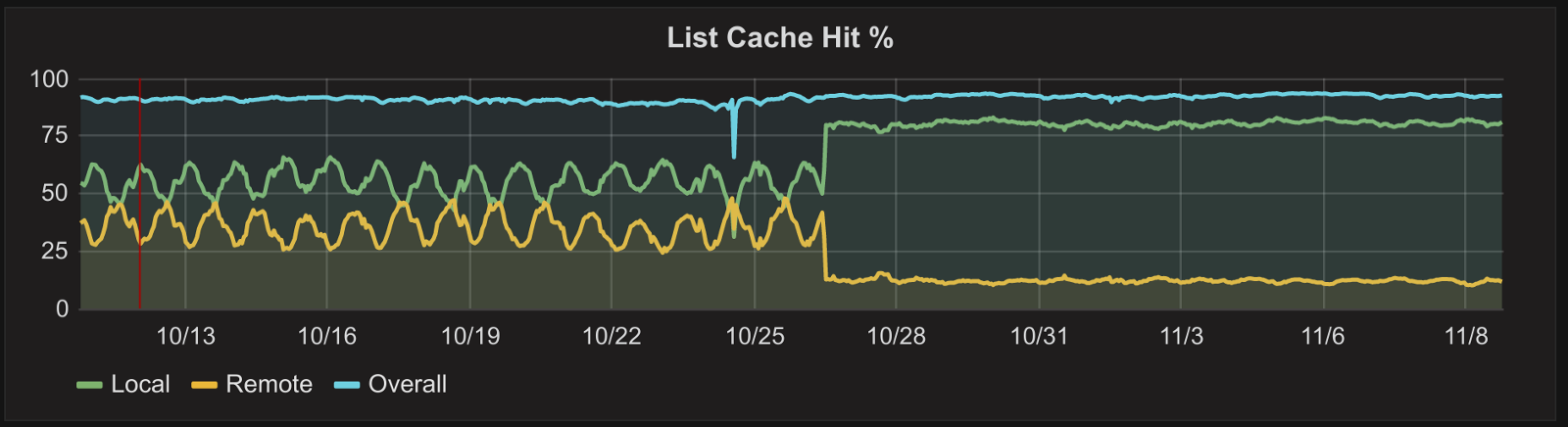
每日变化是由弹性伸缩引起的:在白天,流量会增加,因此我们启动更多服务器来处理它,本地缓存只能解决更少的请求。在晚上,流量较少,因此关闭服务器,本地缓存性能有所提升。切换到有界负载算法后,无论运行多少台服务器,都会有更大比例的请求到达本地缓存。
下面是共享缓存带宽在同一时间的图表:在更改之前,每个memcache服务器在高峰时段的出站带宽达到400到500 Mbit / s(总共大约8Gbit / s)。改进算法之后,变化较小,服务器带宽保持在100 Mbit / s以下。
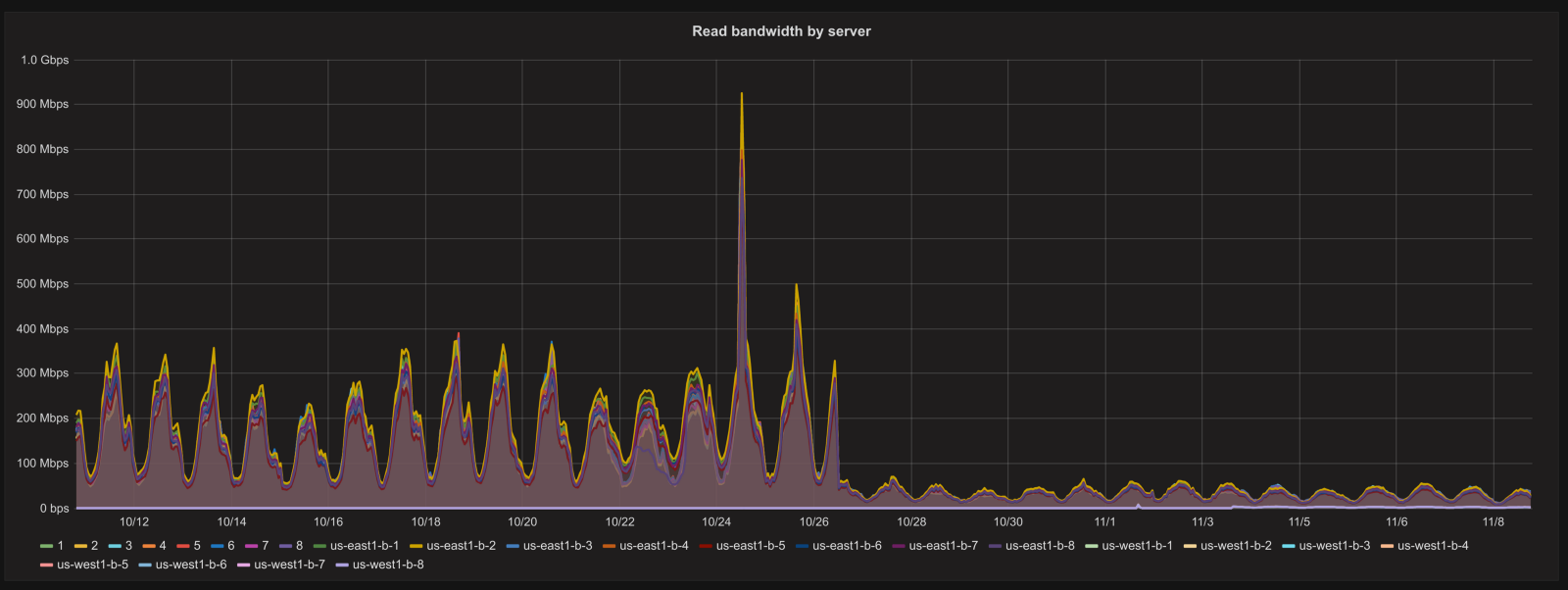
从响应时间的角度来看,我们没有画出性能提升的图。为什么?因为他们保持几乎完全相同。最少连接策略在保持服务器不会过载方面做得很好,从memcache中获取内容的速度足够快,以至于它对响应时间没有可测量的影响。但是现在更少部分的请求会依赖于共享缓存,并且由于该部分不依赖于我们运行的服务器数量,因此我们可以期待在不使memcached服务器饱和的情况下处理更多流量。此外,如果memcache服务器出现故障,它对Skyfire的整体影响将会大大降低。
总而言之,很高兴看到一点算法工作将单点问题变得更好。