之前写过一篇是tcp是流的一些思考–拆包和粘包,是我自己对这个问题的一些认识,毕竟见识浅薄,所言不成系统。今天看到了之前看过的一篇文章,正是对这个问题的一些深入解释,特转载于此,与大家共享。
转载自《TCP/IP高效编程 改善网络程序的44个技巧》–技巧6:记住TCP是一种流协议
TCP是一种流协议(stream protocol)。这就意味着数据是以字节流的形式传递给接收者的,没有固有的”报文”或”报文边界”的概念。从这方面来说,读取TCP数据就像从串行端口读取数据一样–无法预先得知在一次指定的读调用中会返回多少字节。
为了说明这一点,我们假设在主机A和主机B的应用程序之间有一条TCP连接,主机A上的应用程序向主机B发送一条报文。进一步假设主机A有两条报文要发送,并两次调用send来发送,每条报文调用一次。很自然就会想到从主机A向主机B发送的两条报文是作为两个独立实体,在各自的分组中发送的,如图2-25所示。

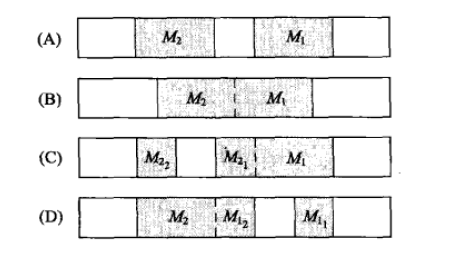
但不幸的是,实际的数据传输过程很可能不会遵循这个模型。主机A上的应用程序会调用send,我们假设这条写操作的数据被封装在一个分组中传送给B。实际上,send通常只是将数据复制到主机A的TCP/IP栈中,就返回了。由TCP来决定(如果有的话)需要立即发送多少数据。做这种决定的过程很复杂,取决于很多因素,比如发送窗口(当时主机B能够接收的数据量),拥塞窗口(对网络拥塞的估计),路径上的最大传输单元(沿着主机A和B之间的网络路径一次可以传输的最大数据量),以及连接的输出队列中有多少数据。更多与此有关的内容请参见技巧15。图2-26只显示了主机A的TCP封装数据时可能使用的诸多方法中的4种。在图2-26中,M11和M12表示M1的第一和第二部分,M21和M22与之类似。如图2-26所示,TCP不一定会将一条报文的全部内容都放在一个分组中传送出去。
现在,我们从主机B应用程序的角度来看这种情形。总的来说,主机B应用程序任意一次调用recv时,都不会对TCP发送给它的数据量做任何假设。比如,当主机B应用程序读取第一条报文时,可能会出现下列4种结果。
实际上,可能的结果不止4种,但我们忽略了出错和EOF之类的结果。我们还假设应用程序读取了所有可读的数据。
没有数据可读,应用程序阻塞,或者recv返回一条指示说明没有数据可读。到底会发生什么情况取决于套接字是否标识为阻塞,以及主机B的操作系统为系统调用recv指定了什么样的语义。
应用程序获取了报文M1中的部分而不是全部数据。比如,发送端TCP像图2-26D那样对数据进行分组就会发生这种情况。
应用程序获取了报文M1中所有的数据,除此之外没有任何其他内容。如果像图2-26A那样对数据分组就会发生这种情况。
应用程序获取了报文M1的所有数据,以及报文M2的部分或全部数据。如果像图2-26B或图2-26C那样对数据进行分组就会发生这种情况。
注意,这里还有一个定时问题。如果主机B的应用程序在主机A发送了第二条报文之后一段时间内都没有读取第一条报文,那么这两条报文都会成为可读的。这就和图2-26B所示情况相同了。这些描述说明,通常,在任意指定时刻,可读的数据量都是不确定的。
需要再次说明的是,TCP是一个流协议(stream protocol),尽管数据是以IP分组的形式传输的,但分组中的数据量与send调用中传送给TCP多少数据并没有直接关系。而且,接收程序也没有什么可靠的方法可以判断数据是如何分组的,因为在两次recv调用之间可能会有多个分组到来。
即使接收端应用程序的响应非常及时,也可能会发生这种情况。例如,一个分组丢失了(参见技巧12,在当今的因特网中,这是非常常见的情况),而且后继分组都安全到达,TCP会将后继分组中的数据保存起来,直到重传第一个分组并正确收到为止。此时,所有数据对应用程序都是可用的。
TCP会记录它发送了多少字节,以及确认的字节,但它不会记录这些字节是如何分组的。实际上,有些实现在重传丢失分组的时候传送的数据可能比原来的多一些或少一些。这就足以支撑下面再次重复说明的内容了。
对TCP应用程序来说,就没有”分组”这种概念。如果应用程序的设计与TCP对数据的分组方式有所关联,就应该考虑重新设计这个应用程序了。
既然任意一次指定的读操作中返回的数据量都是不可预测的,就必须在应用程序中做好应对这种情况的准备。通常这不是什么问题。比如说,我们可能在用fgets这样标准的I/O库程序读取数据。在这种情况下,fgets会将字节流划分成行。图3-6显示了一个这样的例子。在其他情况下的确需要关注报文边界问题,而这些情况下边界都是由应用程序级维护的。
最简单的情况就是定长报文。在这种情况下,只需要读取报文中固定数量的字节就可以了。根据前面的讨论,读操作返回的字节数可能小于sizeof(msg)(图2-26D),所以只进行
recv(s, msg, sizeof(msg), 0);
这样的简单调用是不够的。图2-27显示了处理这种情况的标准方法。


函数readn的用法与read非常相似,但在读到len字节,并从对等实体收到EOF,或出现错误之前,它是不会返回的。我们将其定义如下。
#include "etcp.h"
int readn( SOCKET s, char *buf, size_t len );
返回:读取的字节数,出错时返回-1
readn使用的逻辑与从串行端口,或者从其他基于流的、在任意指定时间内可读取数据量都未知的源端,读取指定数量的字节所使用的逻辑一样,这不足为奇。实际上,在所有这些情况下都可以,也经常使用readn(用int代替SOCKET,用read代替recv)。
如果recv调用被信号中断,第11行和第12行的if语句
if ( error == EINTR) /* interrupted? */
continue; /* restart the read*/
会重启recv调用。有些系统会自动重启被中断的系统调用,这种系统就不需要这两行程序了。从另一个角度来看,这两行代码也不会带来什么问题,因此为了实现最大限度的可移植性,最好还是把它们放在那里。
对必须支持可变长报文的应用程序来说,有两种可用的方法。第一种,可以用记录结束标记来分隔记录。如前所述,使用fgets这样标准的I/O程序将报文分成单个行时,就会发生这种情况。使用标准I/O程序时,很自然地会将新行作为记录结束标记使用。但使用这种方法通常会有一些问题。首先,除非在报文主体中从未用到记录结束标记,否则发送程序就要在报文中扫描这些标记,对其进行转义,或者编码,以免将其误认作记录结束标记。比如,如果将记录分隔字符RS作为记录结束标记使用,发送端就要搜索报文主体,找到所有RS字符,并对其进行转义,比如在前面加上一个\。这就意味着要转移数据以便为转义字符腾出位置。当然,还要对出现的所有转义字符进行转义。因此,如果用\作转义字符的话,就要将报文主体中出现的所有\都改成\。
在接收端,必须再次对整条报文进行扫描,这次要移除转义字符,并搜索(未转义的)记录结束标记。使用记录结束标记要对整条报文扫描两次,所以最好只在那些有”自然”记录结束标记的情况下使用,比如用换行符分隔文本行记录的时候。
另外一种处理可变记录的方法是在每条报文前面加上一个首部,这个首部(至少)包含下面的报文长度,如图2-28所示。
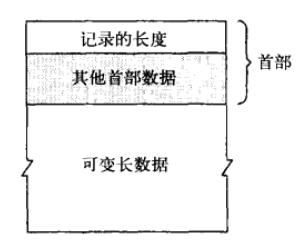
接收端应用程序分两部分读取报文。首先读取定长的报文首部,从首部解析出可变部分的长度,然后读取可变长部分。图2-29显示了一种简单的情况,其中首部只包含了记录的长度。

读取记录长度
6-8 将记录长度读入reclen中,如果readn返回的长度不等于interger类型的大小,readvrec就返回0(EOF),如果出错就返回 1。
9 将记录长度从网络字节序转换为主机字节序。更多相关内容请参见技巧28。
查看是否装得下记录
10-27 查看调用程序的缓冲区大小,验证它能否装下整条记录。如果缓冲区中没有足够的空间,就依次将长度为len的片段读入缓冲区,并将记录丢弃。丢弃记录之后,将errno设置为EMSGSIZE,readvrec返回 1。
读取记录
29-32 最后,读取记录本身。根据readn返回的是错误、不足计数还是成功返回,readvrec会向调用程序返回 1、0或者reclen。
readvrec是个很有用的函数,会在其他一些技巧中用到,所以将其定义记录如下。
#include "etcp. h"
int readvrec( SOCKET s, char *buf, size_t len );
返回:读取的字节数,或者在出错时返回-1
图2-30显示了一个用readvrec从TCP连接中读取变长记录,并将其写入stdout的简单服务器代码。

10-17 初始化服务器,并接受一个连接。
20-24 调用readvrec读取下一个变长记录。如果出错,打印一条诊断信息,并读取下一条记录。如果readvrec返回一个EOF,就打印一条提示消息,服务器退出。
26 将记录写入stdout。
图2-31显示了对应的客户端程序,这个程序从其标准输入读取报文,附加上报文长度,然后将其发送给服务器。

定义分组结构
6-10 定义packet结构,调用send时用它来装载报文及其长度。数据类型u_int32_t是一个无符号的32比特整数。由于Windows没有定义这种数据类型,所以在Windows版本的skel.h中有它的typedef。
对这个例子来说,还应该弄清楚另一个潜在的问题。假定编译器会严格按照我们的指令没有任何填充地将数据封装在一个结构中。因为第二个元素是一个字节数组,所以在大多数系统中这种假设都是有效的,但要小心,对编译器封装数据的方式进行的假设可能会引发一些问题。技巧24对其他一些同时发送两个或多个不同数据段的方法进行了讨论,那时会再次讨论这个问题。
连接、读取并逐行发送
12 客户端通过调用tcp_client连接到服务器。
13-21 调用fgets从stdin中读取一行数据,并将其放入报文分组的buf字段中。行的长度由对strlen的调用决定,将这个值转换成网络字节序后,放入报文分组的reclen字段中。最后,调用send向服务器发送分组。
发送这些由两个或多个部分组成的报文的另一种方法请参见技巧24。
在sparc上启动服务器vrs,然后在bsd上启动客户端vrc,来测试这些程序。将程序的运行并排显示出来,就可以看到客户端的输入,以及相应的服务器输出了。第4行还对错误消息进行了换行显示。

服务器缓冲区有10字节,所以发送11字节1, …, 0,
##小结
初级网络程序员最常犯的错误之一就是无法理解TCP传送的是一个没有记录边界概念的字节流。这一点很重要,可以总结为TCP中没有用户可见的”分组”概念,它只是传送了一个字节流,我们无法准确地预测在一个特定的读操作中会返回多少字节。在这个技巧中,还对应用程序处理这种情况时所使用的几种策略进行了研究。