##TCP和UDP的工作过程
UDP的工作过程是简单的,仅仅将用户数据封装到一个IP数据报中发送到目的地而已,而不关注其他方面。
TCP却是一个极其复杂的协议,以下只是冰山一角
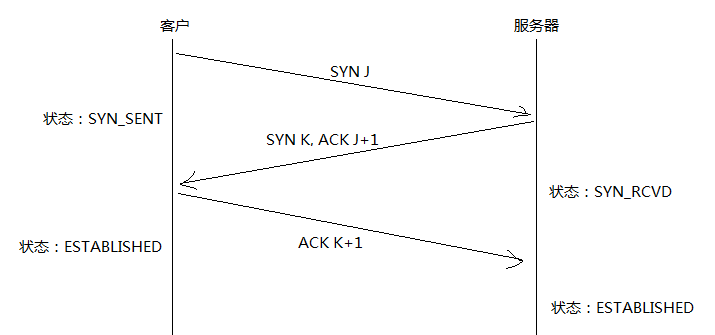
###建立连接的三次握手
- 主动方发送(SYN J),进入SYN_SENT状态
- 被动方收到(SYN J),并往回发送(SYN K, ACK J+1),进入SYN_RCVD状态
- 主动方收到(SYN K, ACK J+1),并往回发送(ACK K+1),进入ESTABLISHED状态
- 被动方收到(ACK K+1),也进入ESTABLISHED状态
以上过程如下图所示:
注意到在TCP三次握手的过程中,服务器有这么一条:
被动方收到(SYN J),并往回发送(SYN K, ACK J+1),进入SYN_RCVD状态
服务器进入SYN_RCVD状态(此时连接称为半开连接)后,应当期待再收到一个ACK。 如果超时未收到客户端的ACK,服务器将重发(SYN K, ACK J+1)。 于是,就有一种叫做SYN Flooding的攻击方式。 攻击者向服务器高速发送(SYN J)(而且可以将SYN分节中的IP地址设为随机数), 并且在随后收到服务器回复的(SYN K, ACK J+1)之后不再继续回复, 这使得服务器上存在很多的半开连接,这些半开连接一般情况下会持续63秒 (在Linux下,默认重试次数为5次,重试的间隔时间从1s开始每次都翻倍,5次的重试时间间隔为1s, 2s, 4s, 8s, 16s,第5次发出后还要等32s才知道第5次也超时了,所以,总共需要 1s + 2s + 4s+ 8s+ 16s + 32s = 63s,TCP才会把断开这个连接)。 它的危害有两方面,一方面自然是占用了服务器的资源;另一方面是填充了半开连接的队列,使得合法的SYN分节无法排队。
根据SYN Flooding的攻击原理,它的防范主要有以下措施:
- 过滤掉最大嫌疑攻击的IP或IP段
- 将tcp_synack_retries设为0,表示回应第二个握手包(SYN K, ACK J+1)给客户端后,如果收不到ACK,不进行重试,加快回收“半开连接”。
- 将tcp_max_syn_backlog参数根据内存情况适当调大,该参数一般指的是维护的半开连接的队列的长度(不同OS不一样)。
- 设置tcp_abort_on_overflow选项,处理不过来就直接拒绝掉。
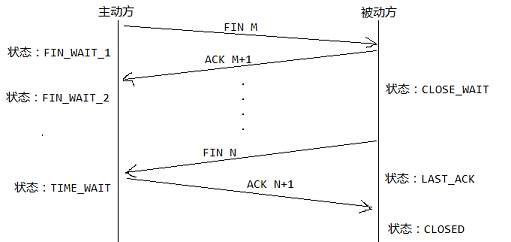
###断开连接的四次握手
- 主动方发送
(FIN M),进入FIN_WAIT_1状态 - 被动方收到
(FIN M),并往回发送(ACK M+1),进入CLOSE_WAIT状态 - 主动方收到
(ACK M+1),进入FIN_WAIT_2状态 - 被动方发送
(FIN N),进入LAST_ACK状态 - 主动方收到
(FIN N),并往回发送(ACK N+1),进入TIME_WAIT状态 - 被动方收到
(ACK N+1),进入CLOSED状态 - 主动方在
TIME_WAIT状态中超时后,进入CLOSED状态
以上过程如下图所示:
其实就是2次,只不过TCP是全双工的,所以,发送方和接收方都需要FIN和ACK。 只不过,有一方是被动的,所以看上去就成了所谓的4次挥握手。
注意到最后有这么一条涉及到TIME_WAIT的状态
主动方在TIME_WAIT状态中超时后,进入CLOSED状态
需要经过一个TIME_WAIT超时的状态而不是直接进入CLOSED的原因有两个,一是确保有足够的时间让对端收到ACK,二是允许老的分节在网络中慢慢的消逝。
然而,如果系统中存在着大量的短链接,那么大量的TIME_WAIT状态就会成为系统的累赘。网上一些资料提到的tcp_tw_reuse和tcp_tw_recycle选项来解决这个问题,但是最好还是别乱用,好像coolshell中有提到过,可能会出很多诡异的问题。还可以调整tcp_max_tw_buckets,当并发的TIME_WAIT过多时,会直接把多的给destory掉,然后在日志里打一个警告。引用一句“其实,TIME_WAIT表示的是你主动断连接,所以,这就是所谓的"no zuo, no die"。
##TCP连接在“非正常”情况下的工作状况
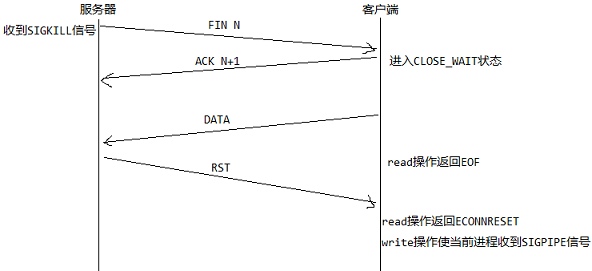
###服务器进程终止
首先,服务器进程终止(收到SIGKILL信号)。作为进程中止处理的工作之一,该进程所有打开着的描述符将被关闭,这会导致向对端(客户端)发送(FIN N),而客户端则回复(ACK N+1),这就是TCP断开连接的前半部分。
然后,此时客户端收到(FIN N)并不意味着连接断开(虽然在这个例子中,确实断开了),只是意味着服务器不再向客户端发送数据了,客户端还可以继续向服务器发送数据。如果此时客户端还继续向服务器发送数据,服务器TCP将发现之前的打开该套接字的进程已终止,于是回应一个RST。客户端在收到这个RST之前的read操作将会返回EOF,在收到这个RST后的read操作会返回ECONNRESET错误,在收到这个RST后的write操作会使当前进程收到SIGPIPE信号。
以上过程如下图所示:
###服务器主机崩溃
服务器主机崩溃的意思是,没有任何预兆,来不及在网络上发送任何消息,主机就无法工作了。这种情况等价于直接切断网络,或者通俗的说,可以直接拔掉网线来模拟这一情况。
这时,如果客户端向服务器发送数据,后调用read操作,TCP会一直等待服务器的ACK确认消息,并且不断的超时重传(按照Berkeley的实现,重传12次,共需9分钟),直到到达重传次数,返回ETIMEOUT错误。如果是由中间的路由器判定服务器主机不可达,响应“destination unreasonable”的ICMP消息,将返回EHOSTUNREACH和ENETUNREACH错误。
###服务器主机崩溃后重启
重启之后的服务器已经丢失了之前的TCP信息,所以即使收到了客户端发来的TCP数据,也会回复RST,往后的情况和“服务器主机崩溃”中提到的类似。
###服务器主机关机
Unix系统关机时,init进程通常会给其他进程发送SIGTERM信号,然后等待10s左右给仍在运行的进程发送SIGKILL信号。所以如果进程不捕获SIGTERM信号,则将由SIGKILL信号终止,和“服务器进程终止”中提到的类似。
##参考链接
TCP 的那些事儿(上)