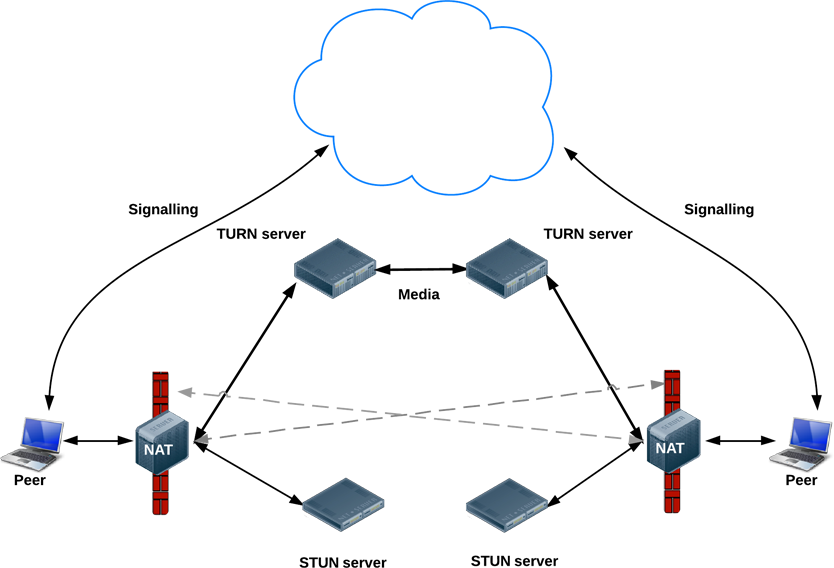
场景
nginx代理了两台socket.io服务器。socket.io的工作模式是polling升级到websocket
现象
通过nginx请求服务时,出现了大量的400错误,有时候能升级到websocket,有时候会一直报错。但是直接通过ip+端口访问时,100%能成功。

分析
sid
sid是我们这个问题的关键。在初始创建连接时(polling模式就是在模拟一个长连接),客户端会发起这样的请求:
|
|
服务端收到后会创建一个对象,绑定在这个连接上,同时返回一个sid(session id),来标记这个会话。会话指什么呢,会话是一连串的交互,这些交互之间是有联系的,在我们这个场景下就是,下一次的http请求到来,我需要找到之前绑定在理论上的长连接(这里还没有websocket,所以是理论上的)上的那个对象。我们知道http请求是无状态的,每个请求之间独立,所以socket.io引入了sid来做这件事。服务端收到请求后会生成一个sid,看下response:
|
|
之后每次请求都需要带上这个sid,建立websocket请求的连接也不例外。所以说,sid是polling,以及polling升级到websocket的关键。这之后的请求类似于:
|
|
那么问题来了,如果请求是带上的sid不是服务端生成的会怎样呢?服务端会不认识,给你返回一个400,并告诉你
|
|
我们遇到的便是这个问题,nginx默认的负载均衡策略是轮询,所以请求有可能会打到不是生成这个sid的机器上去,这时候我们就会收到一个400,如果运气好,可能也会打到原来的机器上,运气更好一点,甚至能坚持到websocket连接建立。
解决
这里提出两种方案
- nginx的负载均衡采用ip_hash,这样能保证一个客户端的请求都走到一台服务器上
- 不使用polling模式,只使用websocket
这两种方案各有利弊。第二种显而易见,不支持websocket的古老浏览器和客户端将没法工作。第一种的问题隐藏得比较深,试想,如果你增减了机器会怎样,这时候ip_hash策略的模将变化,之前的连接将全部失效,而对于微服务,扩缩容是很频繁的操作(特别是产品处于发展期),这种有损的扩缩容很大概率是不能接受的。
综上,建议直接使用websocket,毕竟不支持websocket的老版本占比很少,而且相对于先polling,耗时也会减少。