预备知识
什么是swarm
一个swarm就是一组运行Docker并组成集群的机器。之后,你继续运行以前使用的Docker命令,但现在它们是由swarm manager(也是一台机器,执行docker swarm init的就是manager)在集群上执行。集群中的机器可以是物理机或虚拟机。加入集群后,它们被称为节点(node)。
swarm manager可以使用几种策略来运行容器,例如“最空的节点”(empties node) - 将容器放到利用率最低的机器上。或者“全局”(global)模式,它确保每台机器只能获得指定容器的一个实例。你通过在compose文件来指示swarm manager使用这些策略。
swarm manager是集群中唯一可以执行命令的机器,也是唯一可以授权其他机器作为worker加入集群的机器。worker只提供capacity,它无法告诉任何其他机器它可以做什么和不能做什么。
什么是slack
stack是一组相互关联的服务,可以被一起编排。单个stack能够定义整个应用程序的功能(尽管非常复杂的应用程序可能希望使用多个stack)。
Set up your swarm
一个swarm由很多node组成,node可以是物理机或虚拟机。基本概念很简单:运行docker swarm init启用集群模式,使当前的机器成为manager,然后在其他机器上运行docker swarm join,使他们以worker身份加入集群。
创建集群
我们可以在本机创建几台虚拟机来创建我们的集群(需要安装VirtualBox)
首先,使用docker-machine命令,通过VirtualBox驱动创建两台虚拟机,myvm1和myvm2:
|
|
我们将myvm1用作manager,它可以执行docker命令和授权别的worker加入swarm,myvm2将作为worker。
登录docker-machine创建的虚拟机可以使用docker-machine ssh命令,下面我们设置myvm1为manager:
|
|
可以看到,返回值中已经有了一个配置好的docker swarm join命令,复制这个命令,在myvm2上执行,使myvm2加入你的swarm作为worker:
|
|
🎉,我们的第一个swarm创建成功了。
我们可以登上myvm1去看看现在的节点情况:
|
|
一目了然,现在有两个node,myvm1是作为leader存在
部署应用
我们使用这个简单的python应用来作为部署对象,你完全可以使用自己的应用程序(但还是建议用我使用的这个程序,这个应用打印了container的hostname,这是下面负载均衡的一个测试)。
首先将docker-compose.yml拷贝到myvm1:
|
|
然后就是部署了:
|
|
这时候部署已经完成了,我们来看看成果:
|
|
可以看到,我们一共有7个container。web5个,分布在两台机器上,redis和visualizer各一个,在manager节点上。这和我们在docker-compose.yml中定义的一样。
myvm1和myvm2的地址都可以访问我们的应用。你创建的网络在它们之间是共享,并且负载平衡的。运行docker-machine ls来获取你的虚拟机的IP地址,并在浏览器上访问它们,并刷新。你会看到五个可能的容器ID,它们随机循环,显示了负载平衡的存在。
两个IP地址都能工作的原因是群集中的节点加入了一个入口路由网格(routing mesh)。这样可以确保在集群中某个端口部署的服务始终将该端口保留给其自己,无论实际运行容器的是哪个节点。以下是在一个三节点集群的8080端口上部署的名为my-web的服务的路由网格示意图:
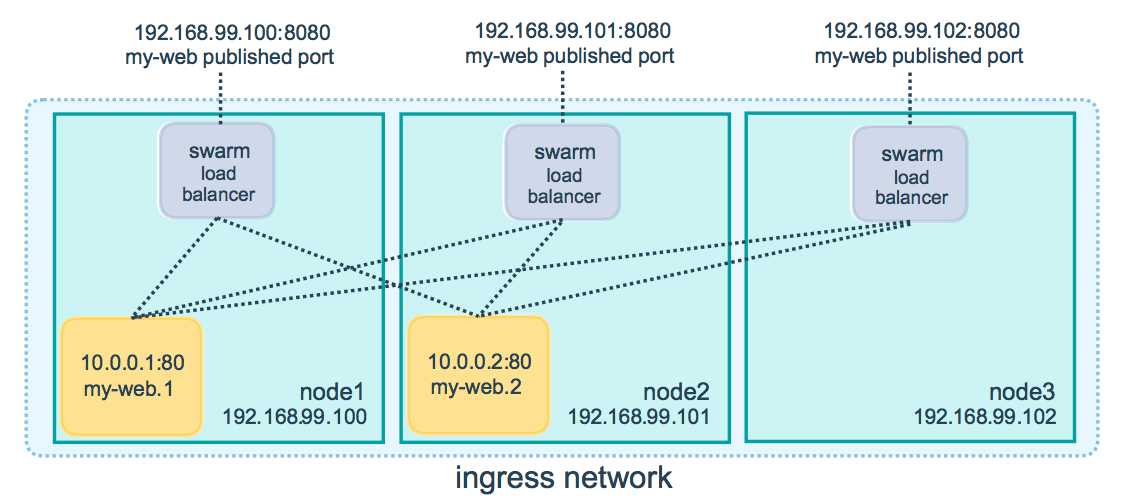
如果想要增加容器个数,只要修改docker-compose.yml文件中的replicas的数量,然后重新执行deploy就可以了。
如果要加入新的node,只要在新的机器上执行我们在myvm2上执行的docker swarm join命令就可以了,加入新的节点后,重新执行deploy,我们就能用上新的机器了(注意要重新执行deploy,不会自动deploy,这一点和elasticsearch等软件不一样)。
因为我们部署了visualizer,可以通过网页来看看我们集群现在的情况:
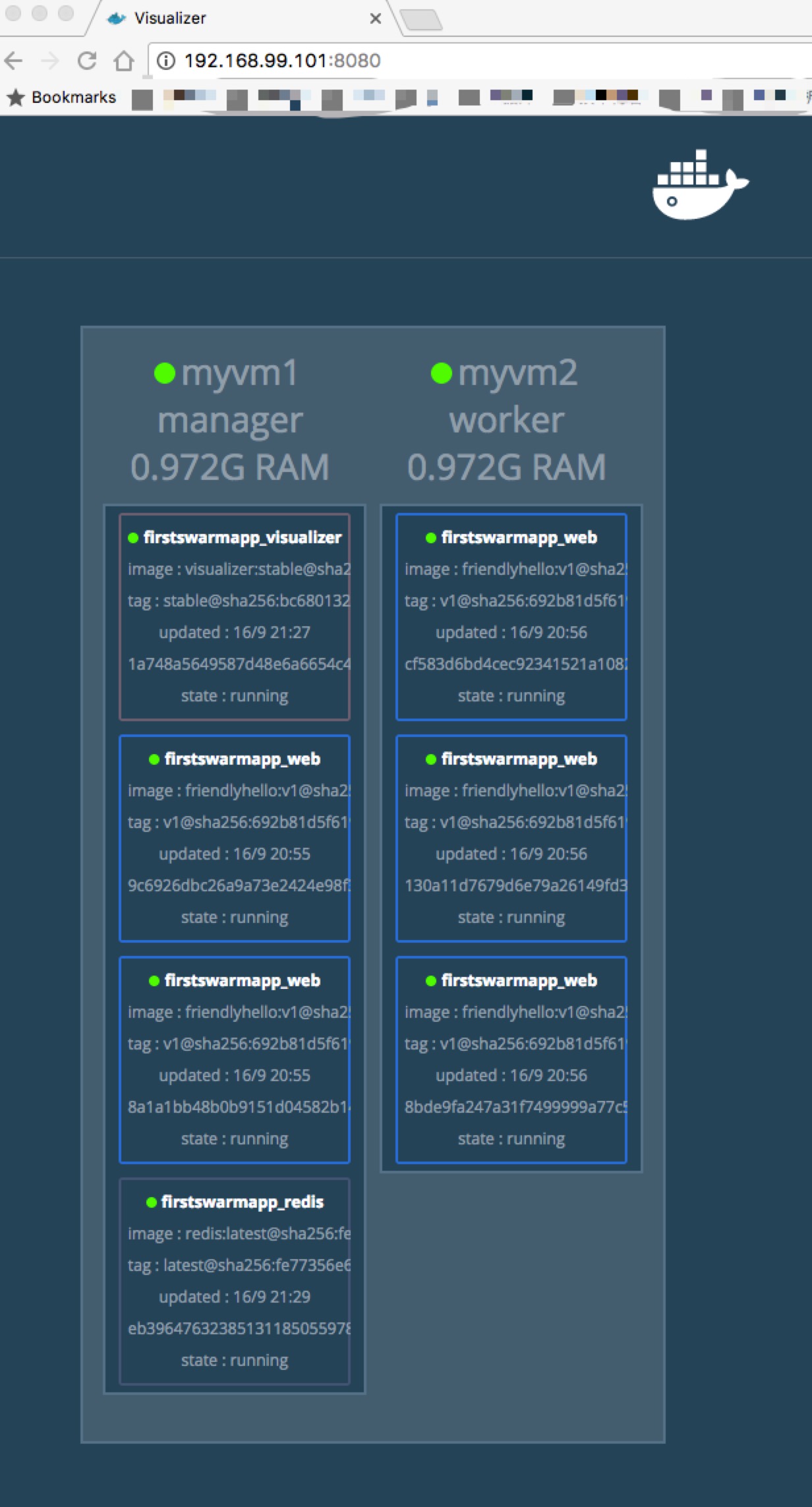
跟docker stack ps输出是一致的。
清理
清理stack
|
|
这时候swarm还是在的,清理swarm:
|
|